Projects / spieeltjie
Spieeltjie is a single-file package for doing simple experiments with multi-agent reinforcement learning on symmetric zero-sum games. For more information see “Open-ended learning in Symmetric Zero-Sum Games”arxiv.org and “A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning”arxiv.org. The name “spieeltjie” comes from the Afrikaans word for “tournament”.
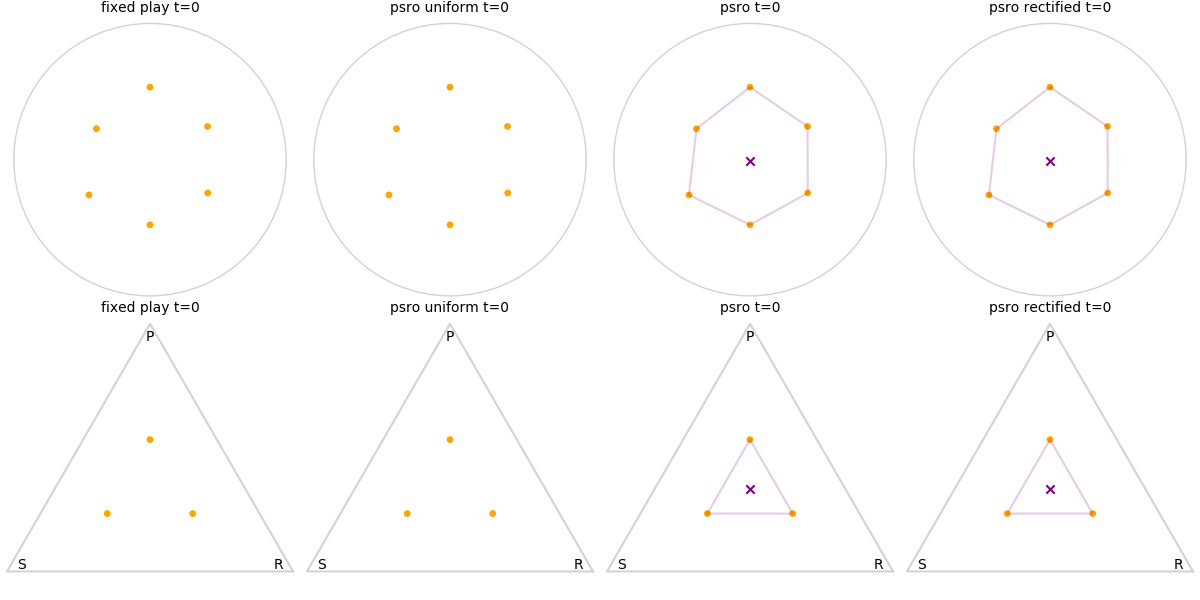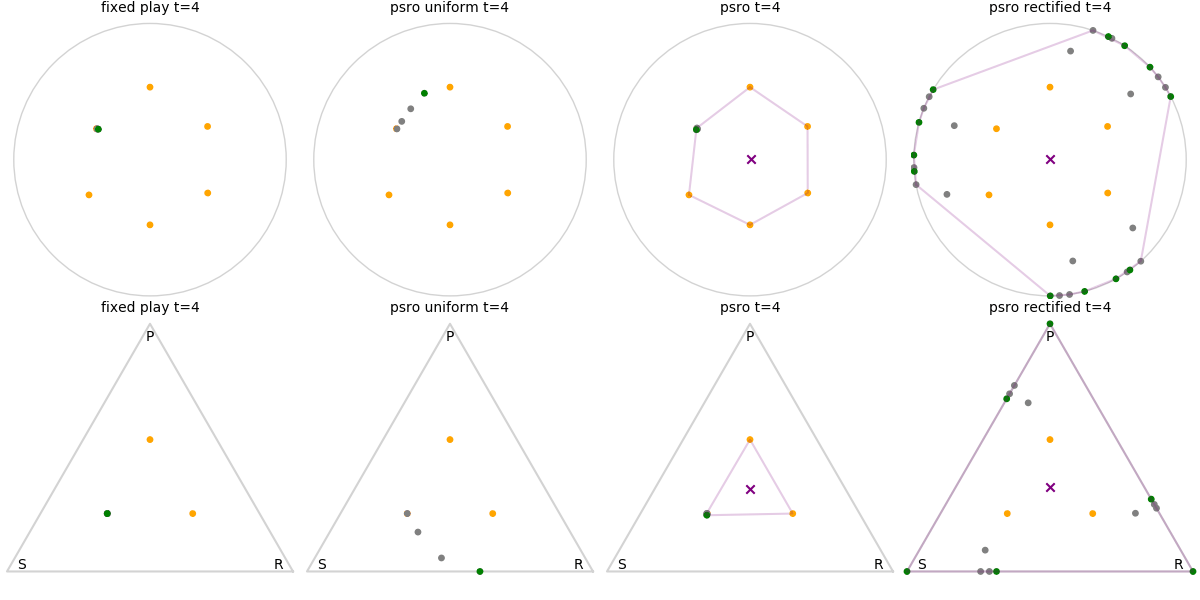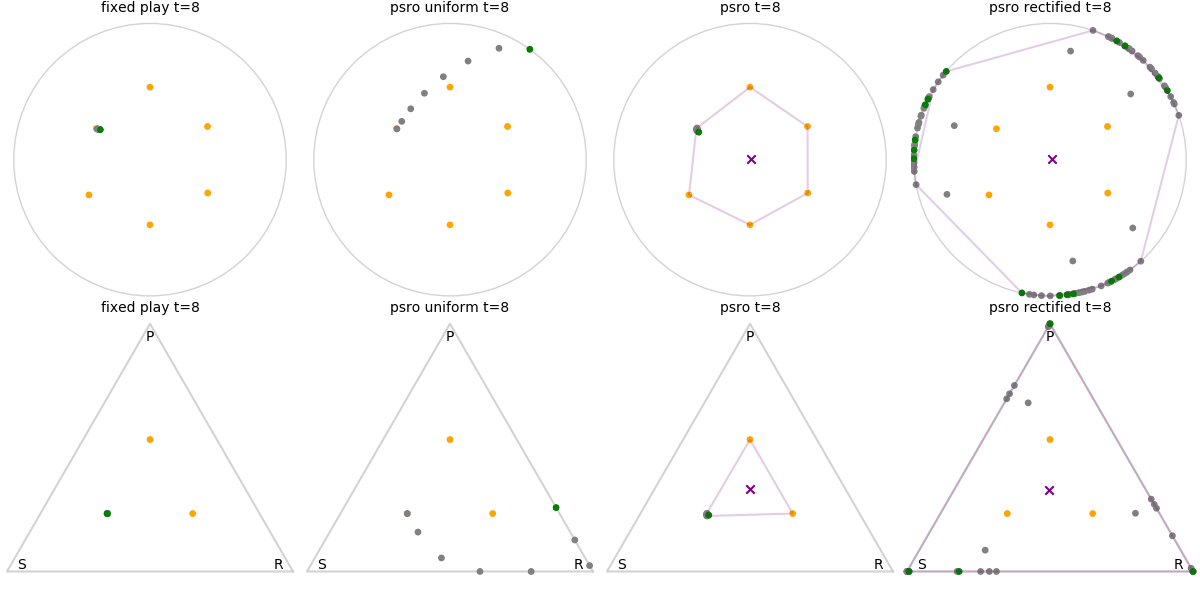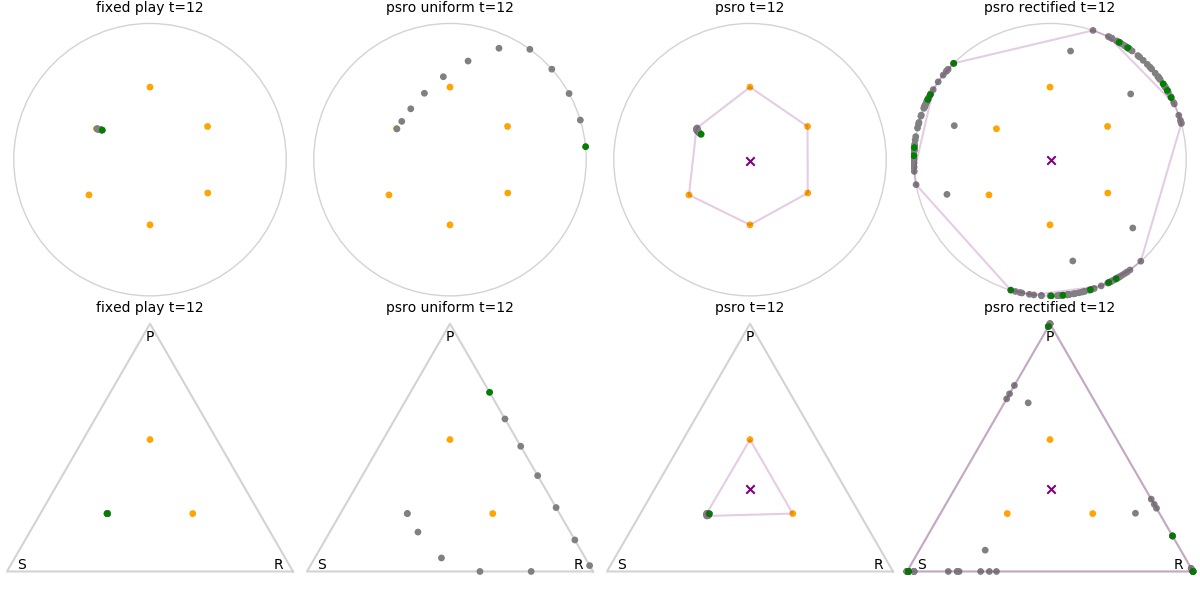
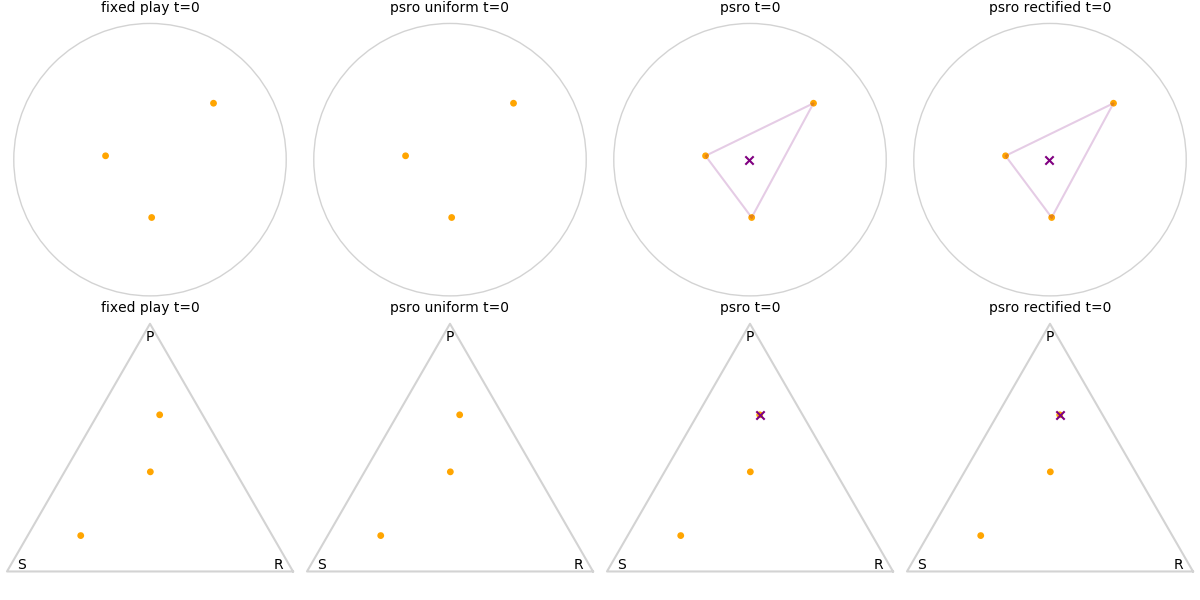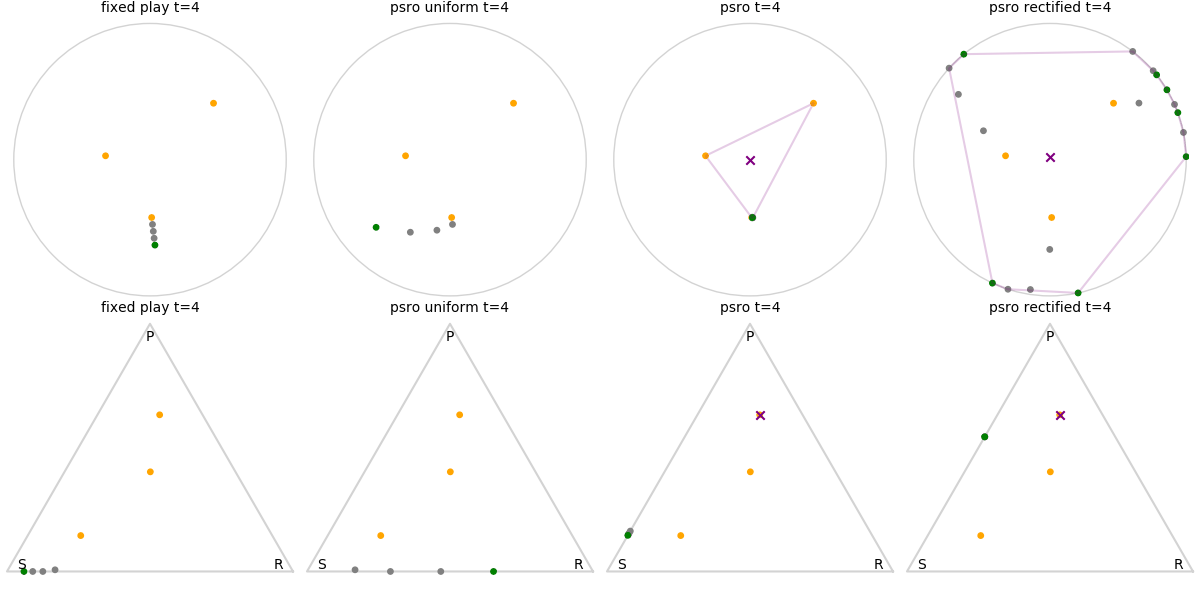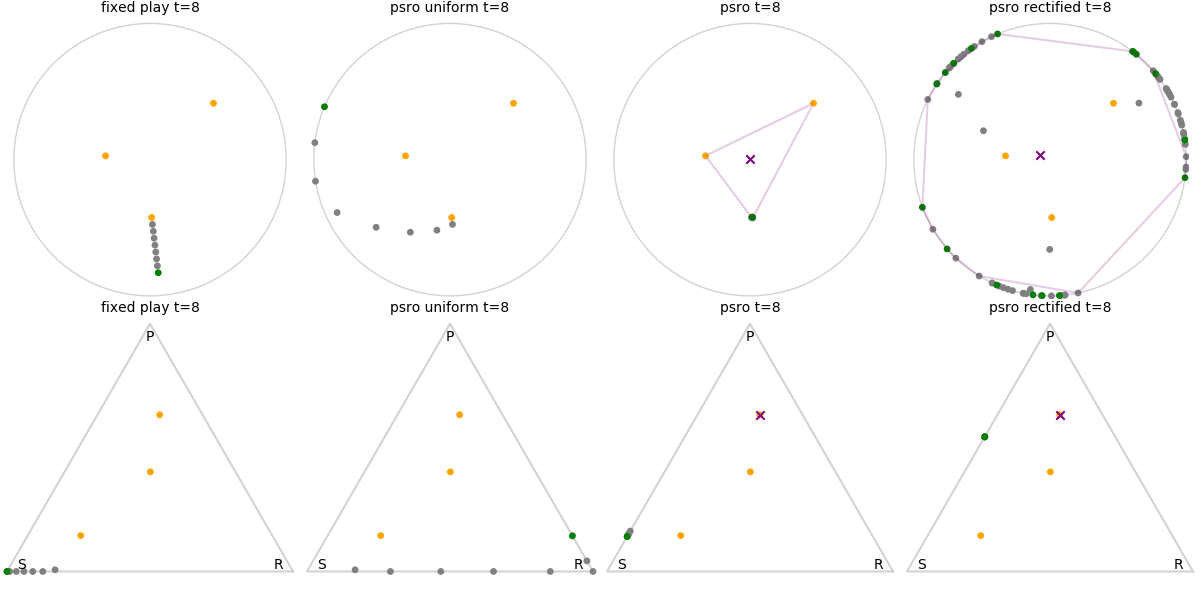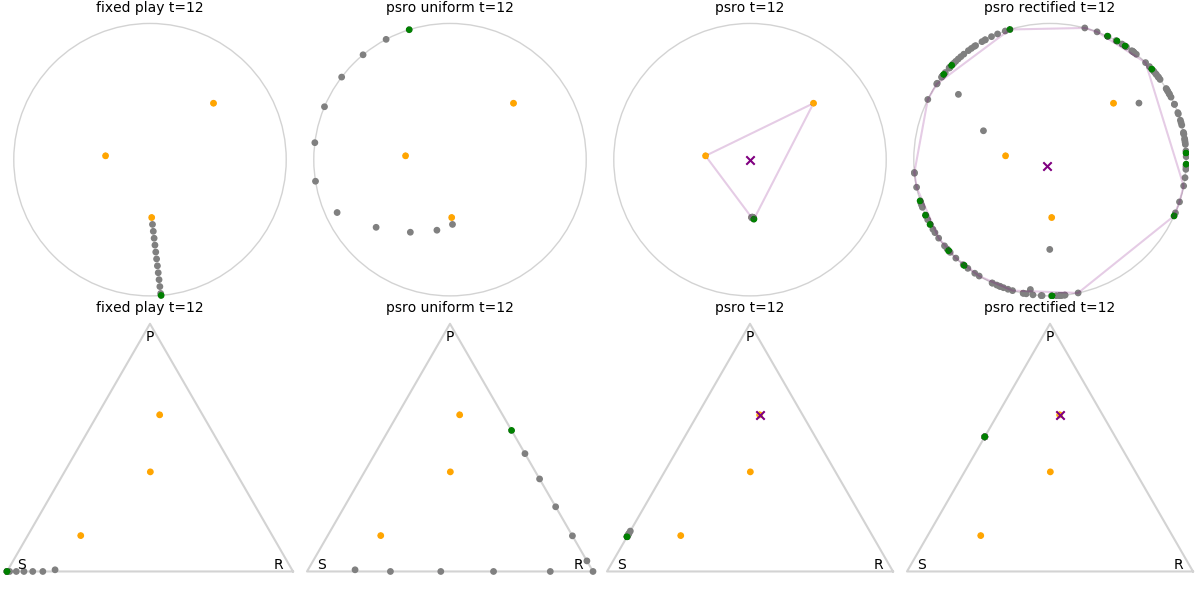
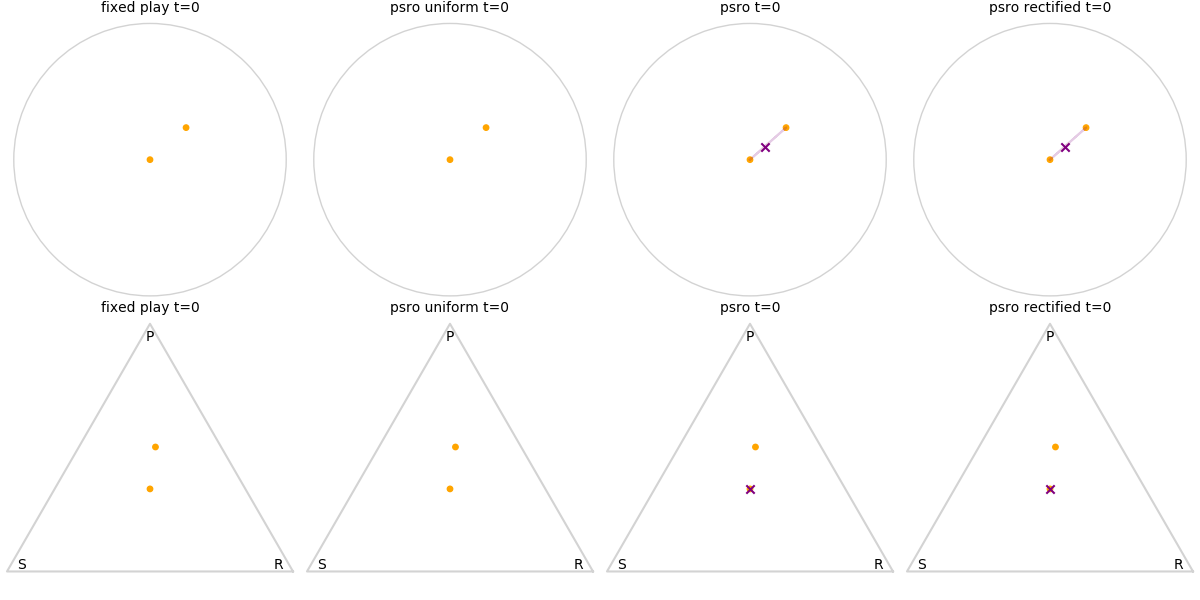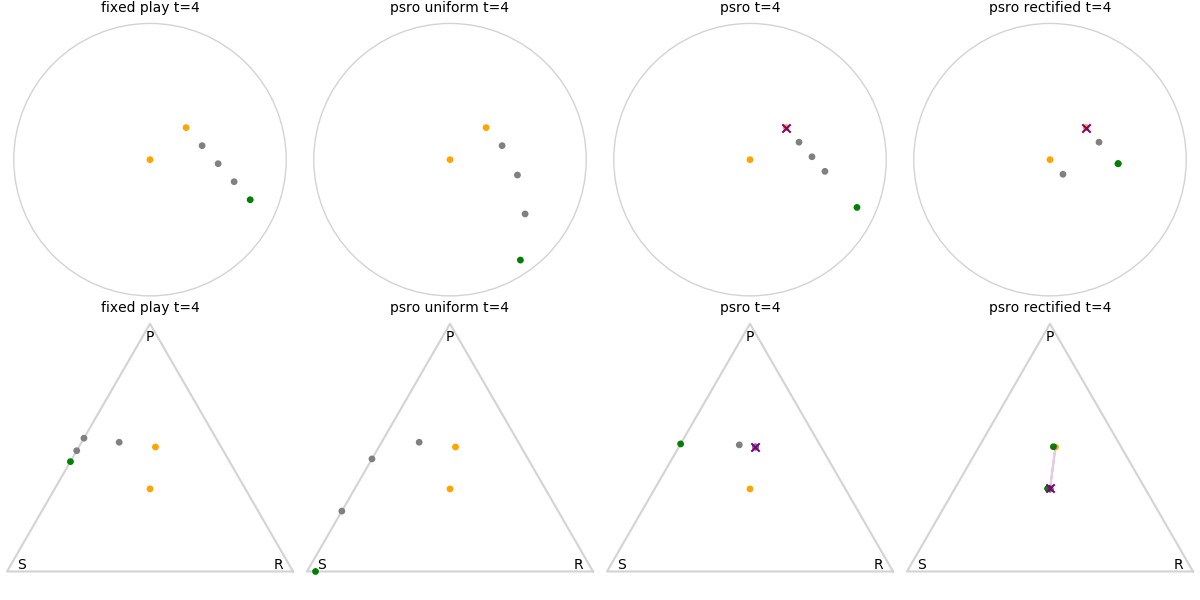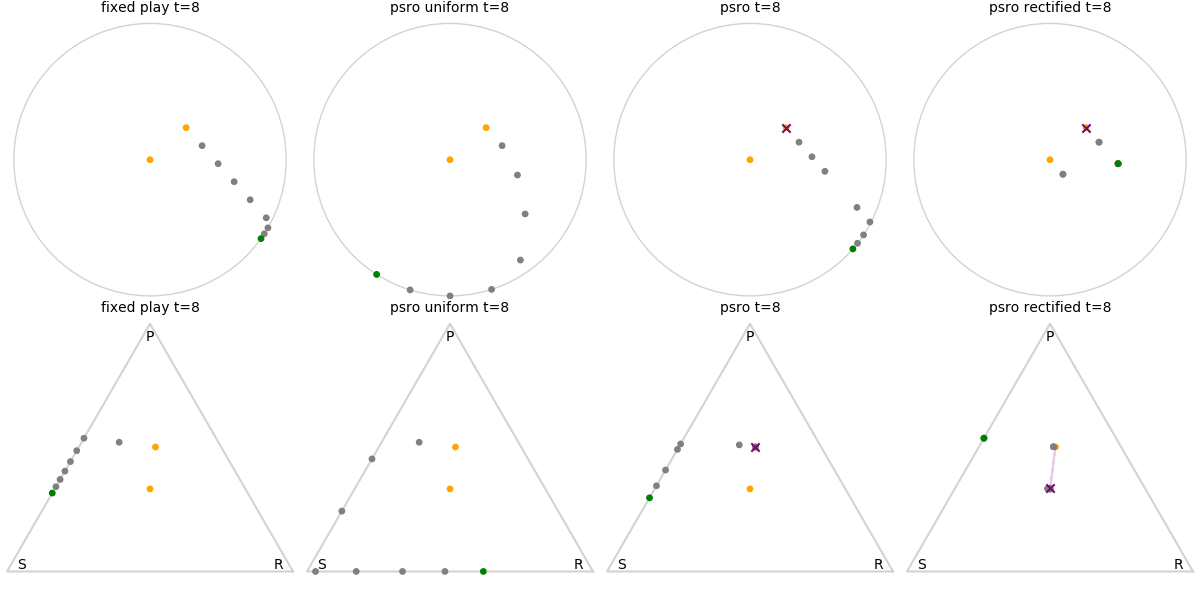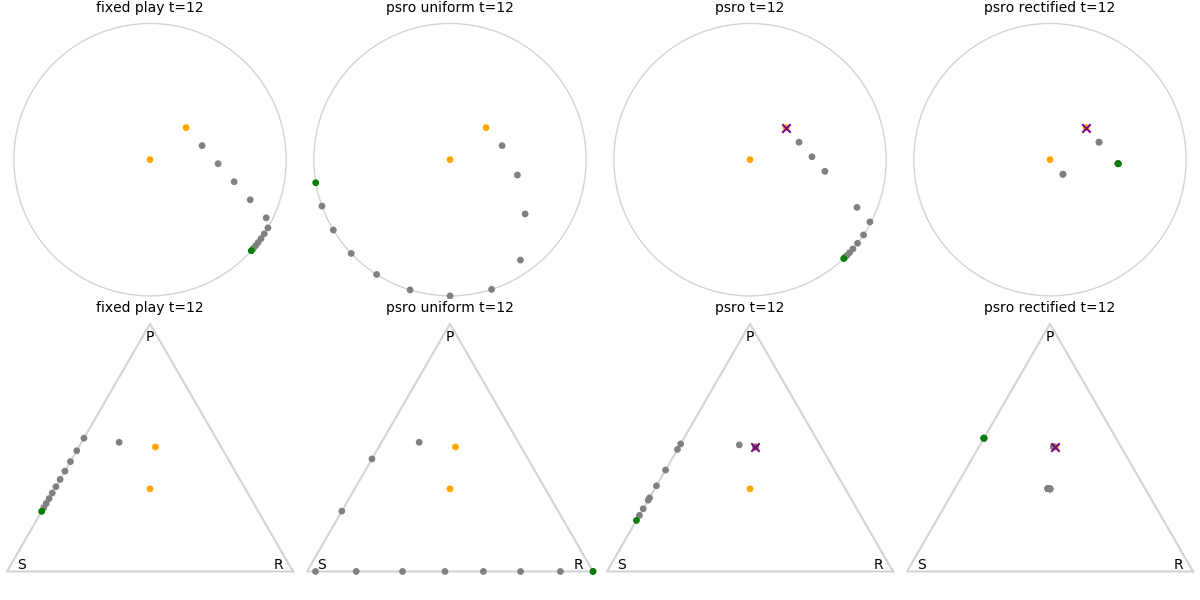
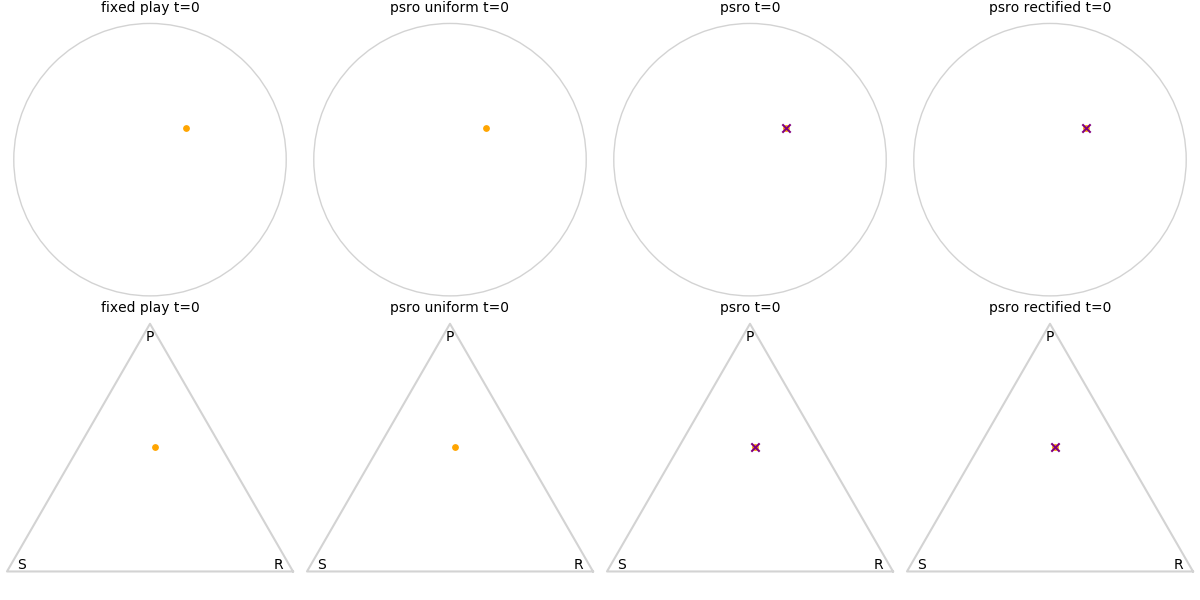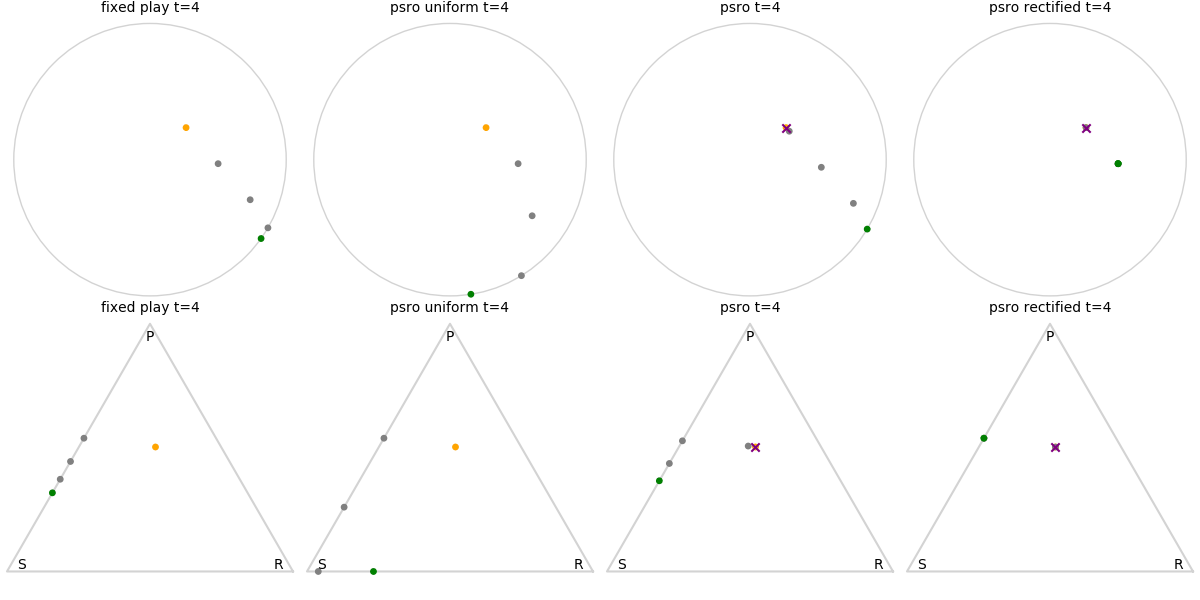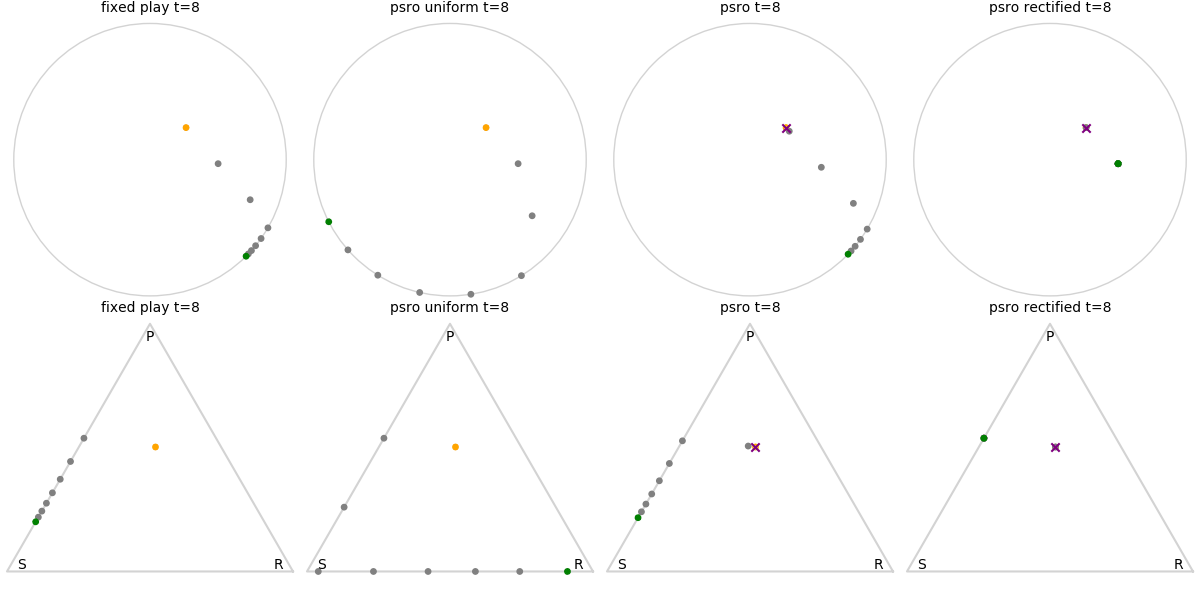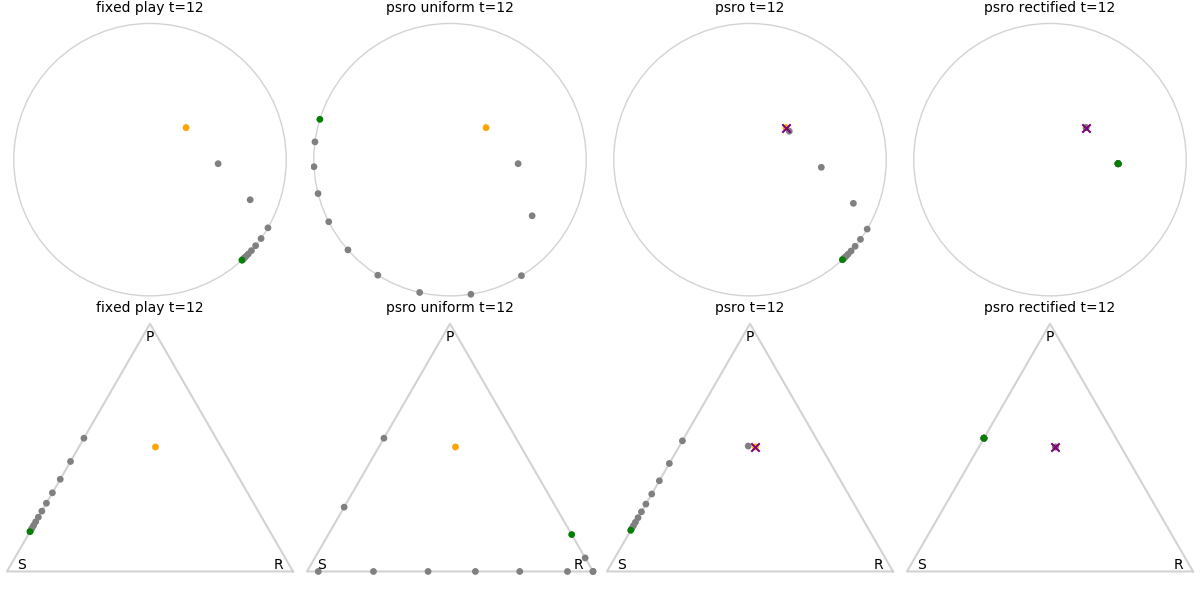
Explanation of animations: The top row is the disk game, the bottom row is Rock Paper Scissors (with agents being mixed strategies). The columns are algorithms, being:
- fixed play: iteratively update one agent against the initial population
- PSRO uniform: update against all previous agents equally
- PSRO nash: update against the empirical nash
- PSRO rectified nash: update all agents with support in the nash against the nash, ignoring stronger opponents
Three random agents
This first set of images shows trajectories when starting from a set of random initial agents (orange points). The purple polygon and cross shows the nash equilibrium for those algorithms that use it (this nash is approximated via fictitious play and so can jump around a bit). Note that some algorithms do not make progress for some initial conditions.
One random agent + one nash
This second set of images shows trajectories when starting from two agents, one of which is already the Nash equilibrium of the functional game.
One random agent
This third set of images show trajectories when starting from a single, random agent.
Well-supported population
This last set of images above shows trajectories when starting from a set of agents that give good coverage of the policy space. They are slightly randomly perturbed to prevent cancellation of gradients that would otherwise effect particular algorithms.